LLM Agents 课程笔记
鉴定为水课,尽量挑感兴趣的有用的部分看。
最近工作内容涉猎了大模型的应用,想更深入的了解一些,便打算试试这门课。笔记更新进度对应学习进度。
LLM Reasoning
提问:What do you expect for AI?
What do you expect for AI?
AI 是人类创造出来的更自动化的工具。若从控制的观点来说,AI 就是控制器的控制器,能够担负人类的现实任务。在理想的应用情况可以承担大部分社会物质精神运转的负荷。
教授的回答:
What do you expect for AI?
AI should be able to learn from a few examples, like what humans usually do
而以往的机器学习达到了这个期望吗?并没有。机器学习缺乏归因能力——需要大样本学习。而”Humans can learn from just a few examples because humans can reason“。因此其暗指大模型拥有 reason 能力。
Key Ideas
我们慢慢引出一系列关键的想法来提升大模型的效果。
Derive the Final Answer through Intermedia Steps
Also called Chain-of-Thought(CoT).
可以简单导出一种应用——CoT Prompting。最经典的一个例子——”Let's think step by step“,这个 Prompting 达成了零样本的 CoT。
Least-to-Most Prompting Enable easy-to-hard generalization by decomposition
《How to Solve It》一文中提到。
Decomposing and recombing are important operations fo the mind. You decompose the whole into its parts, and you recombine the parts into a more or less different whole. If you go into detail you may lose yourself in details.
其实理念和计算机科学中一直倡导的缩小问题规模有共通之处?Map-Reduce,缩小问题规模不可避免地就要分解问题。
Using just 0.1% demonstration examples achieves perfect generalization.
这里不知道是指预训练时加入一定量地分解问题的数据,还是指对话时加入分解问题的例子。
以上两种方法其实都是中间步骤。为什么中间步骤可以有如此大的效果呢?
- Constant-depth transformers can solve any inherently serial problem as long as it generates sufficiently long intermediate reasoning steps
- Transformers which directly generate final answers either requires a huge depth to solve or cannot solve at all
也就是说,没有中间步骤要么注意力强大到能直接解决问题,要么得到错乱的解。而加入中间步骤,解决序列问题中的每一个简单问题,从而可以解决任何能够分解为序列问题的问题。
LLMs as Analogical Reasoners
Do you know a related problem? In fact, when solving a problem, we always profit from previously solved problems, using their result, or their method, or the experience we acquired solving them.
出于这种思想,可以导出提示词——Recall a related problem, and then solve this one. (回忆一个相关问题,然后解决这个问题)。这种方法又叫 Self-generated Examples。
不过提示词的角度太过于简陋,从我个人的角度来说,提示词其实很不安全,而且让我很不安。完全把命运交给多出来的词向量真的太怪了。有没有不使用 Prompting 就可以触发 CoT 的方法?
有的。从 Decode 下手,以往 GPT 输出的时候是选择 Top-k 中概率最高的词输出,也就是简单的贪心选择。如果让其对 Top-k 中的词继续做生成,在根据置信度选择答案,这就是 CoT-decoding 方法。

Key takeaways
- Pre-trained LLMs, without further finetuning, has been ready for step-by-step reasoning, but we need a non-greedy decoding strategy to elicit it.
- When a step-by-step reasoning path is present, KKMs have much higher confidence in decoding the final answer than direct-answer decoding.
Limits of Intermediate Steps
Always keep in mind that LLMs are probabilistic models of generating next tokens. They are not humans.
我们希望:给出问题的基础上得到最大可能的最终答案。
LLM CoT-decoding所做:给出问题的基础上,给出最大可能的 reasoning path 以及最大可能的最终答案。
Self-Consistency
More consistent, more likely to be correct
人性的一个突出方面是人们的思维方式不同。很自然地假设,在需要深思熟虑的任务中,可能有几种方法可以解决问题。我们建议可以通过从语言模型的解码器中采样来在语言模型中模拟这样的过程。例如,如图 1 所示 ,一个模型可以对数学问题生成多个合理的回答,这些回答都得出相同的正确答案(输出 1 和 3)。由于语言模型不是完美的推理器,因此模型也可能产生不正确的推理路径或在其中一个推理步骤中出错(例如,在输出 2 中),但此类解决方案不太可能得出相同的答案。也就是说,我们假设正确的推理过程,即使它们是多种多样的,也往往比不正确的过程在最终答案中具有更大的一致性。
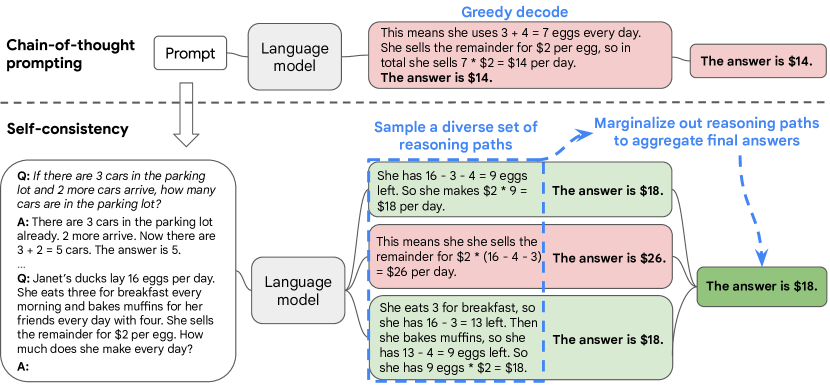
Self-Consistency 利用了复杂的推理任务通常允许多条推理路径到达正确答案的直觉。一个问题越需要深思熟虑的思考和分析 ,可以得到答案的推理路径就越多样化。
Quiz
Q1. When the LLM outputs a direct answer without intermediate steps, will you still sample several times, and then choose the most common answer?
我不会,我倾向于它不能够解决这个问题,而重新换种问法。
Q2. Change self-consistency by letting LLM generate multiple responses, instead of sampling multiple times, and then choosing the most common answer. Does this make sense?
我认为这其实并不能解决问题。首先模型必须能够得出正确答案,假设其起作用的前提是,采样到的答案中正确的答案占大多数。这只能让复杂但不困难的任务表现的更好,而对于简单任务和复杂困难任务没有帮助。
Limitations
大模型存在什么限制呢?了解限制可以让我们更好的发挥它的作用。
LLMs Can Be Easily Distracted by Irrelevant Context
Psychology studies show that irrelevant information may significantly decrease some children and even adults problem-solving accuracy.
在大模型上的表现就是——Adding irrelevant contexts to GSM8K leads to 20+ points performance drop.
知道了如此限制,那么我们可以用提示词去尝试解决——Ignore irrelevant context。这可以挽回一点性能表现。
LLMs Cannot Self-Correct Reasoning Yet
While allowing LLMs to review their generated responses can help correct inaccurate answers, it may also risk changing correct answers into incorrect ones.
尤其是在常识性的问答中,GPT-3.5 Self-Correct 后的表现下降的很厉害。
Reported improvements need oracle answers.
Oracle: Let LLMs self correct only when the answer is wrong
Premise Order Matters in LLM Reasoning
前提条件重排序会让 solving rates 下降。
总结
- Generating intermediate steps improves LLM performance
- Training/fine-tuning/prompting with intermediate steps
- Zero-shot, analogical reasoning, special decoding
- Self-Consistency greatly improves step-by-step reasoning
- Limitation: irrelevant context, self-correction, premise order